用Jsoup写个小爬虫玩玩
初始化
获取请求返回的页面信息,筛选出我们想要的数据就可以了
初始化项目
导入依赖


代码编写
编写一个封装对象的实体类
1 | |
爬取数据
爬取京东页面,可以看出京东keyword可以查询数据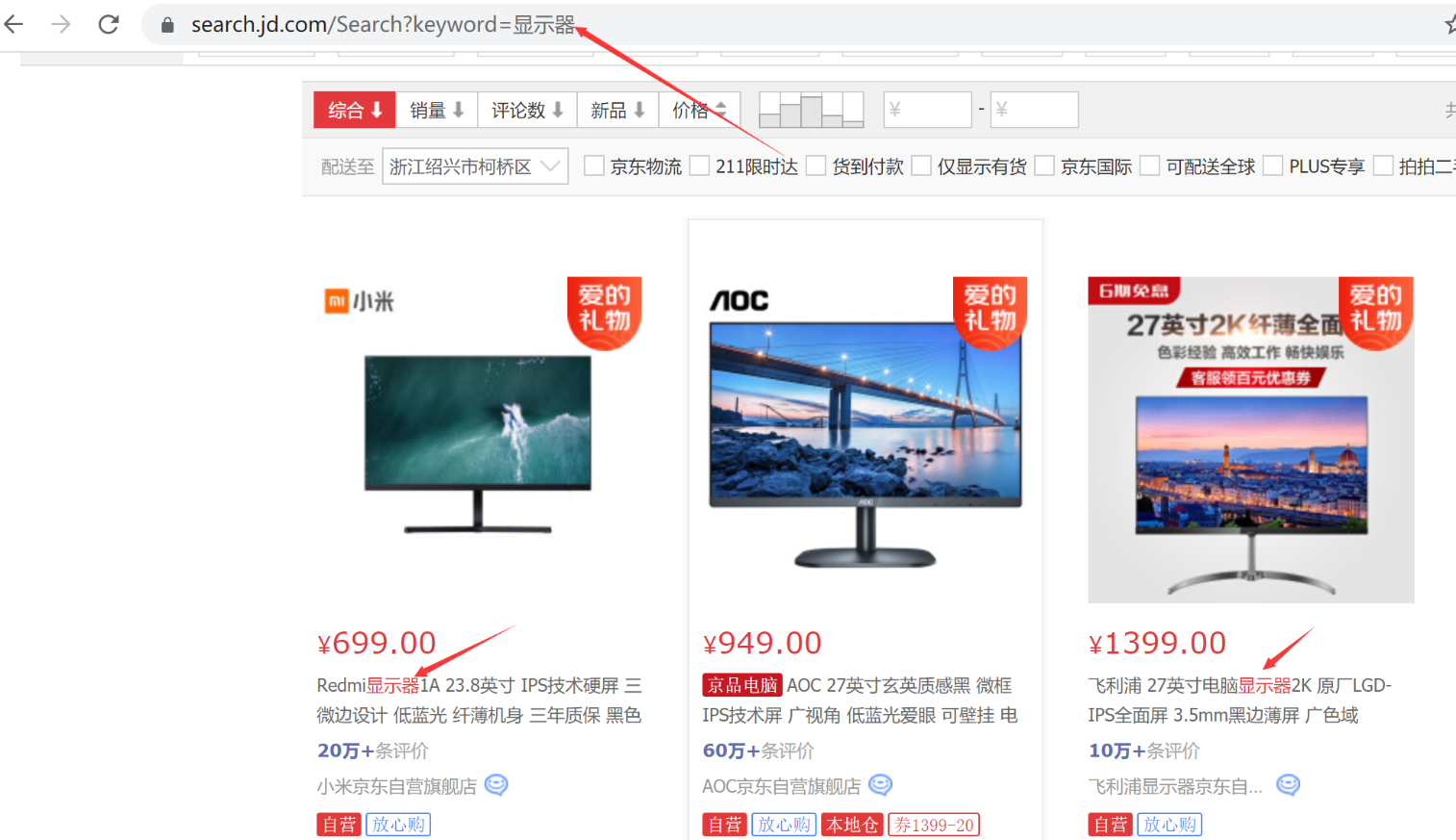
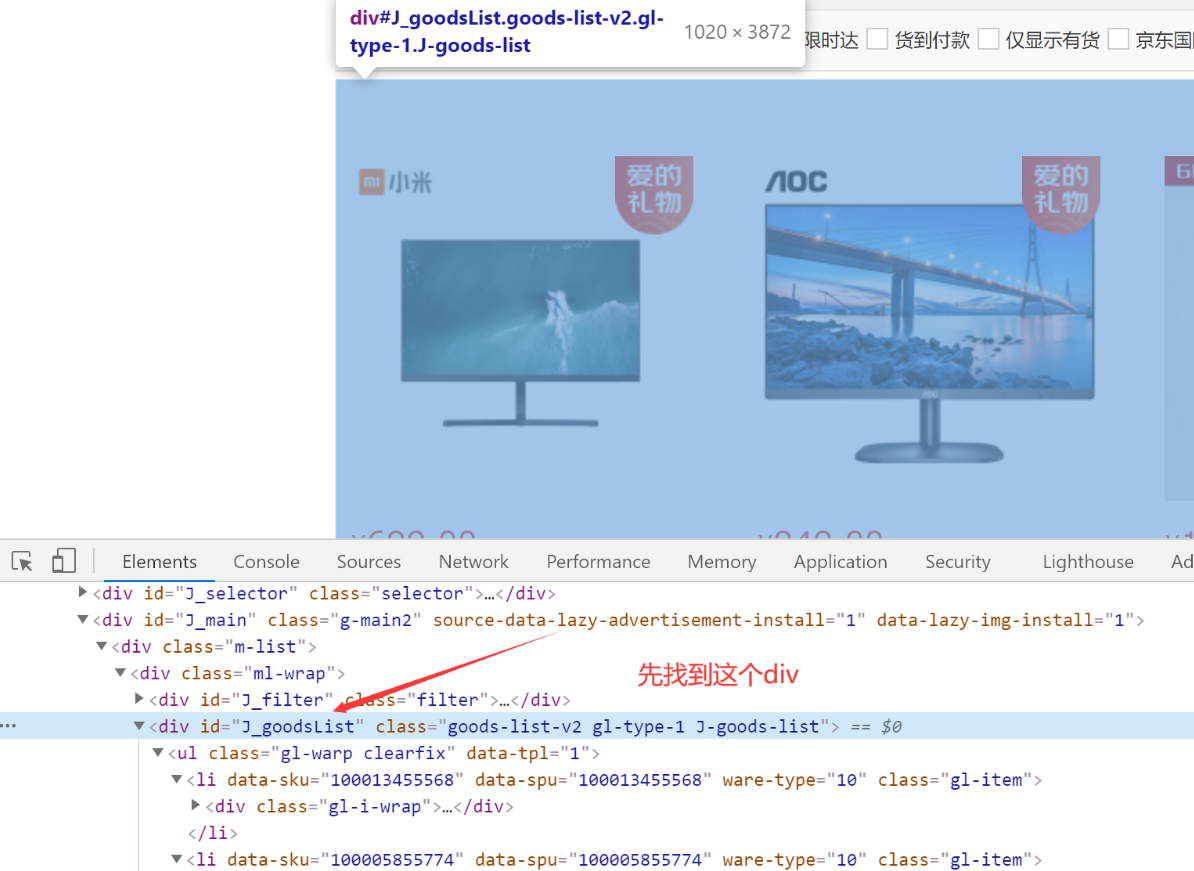
先找到id为J_goodsList的div,然后遍历下面的每个li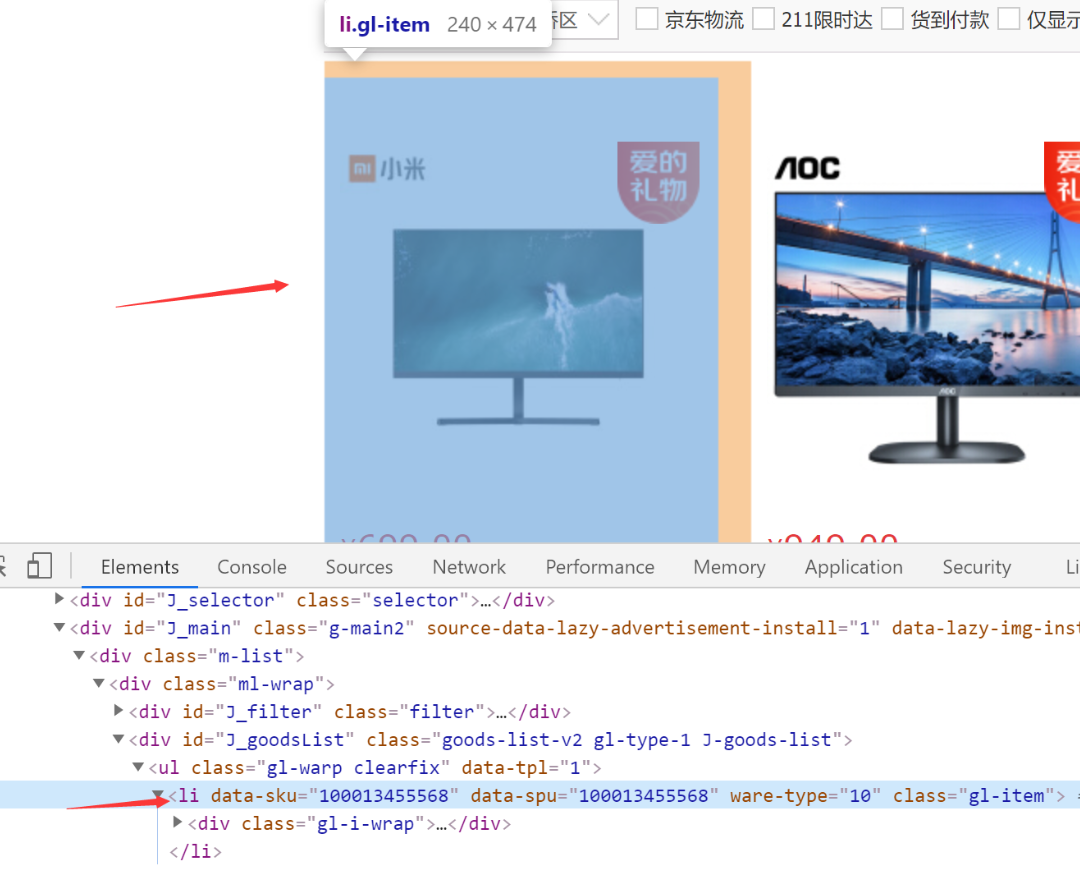
1 | |
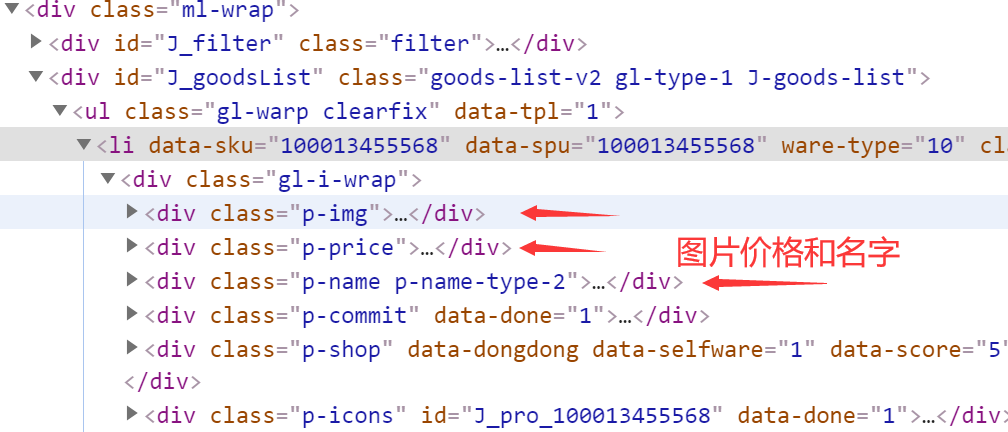
1 | |
完整代码
1 | |

用Jsoup写个小爬虫玩玩
http://example.com/2021/02/11/用Jsoup写个小爬虫玩玩/
获取请求返回的页面信息,筛选出我们想要的数据就可以了
初始化项目
导入依赖
1 | |
爬取京东页面,可以看出京东keyword可以查询数据
先找到id为J_goodsList的div,然后遍历下面的每个li
1 | |
1 | |
1 | |